









Language is all about repetition. Every word you're reading was created by humans, and then used by other humans, creating and reinforcing context, meaning, the very nature of language. As humans train machines to understand language, they're teaching machines to replicate human bias.
“The main scientific findings that we're able to show and prove are that language reflects biases,” said Aylin Caliskan of Princeton University's Center for Information Technology Policy. “If AI is trained on human language, then it's going to necessarily imbibe these biases, because it represents cultural facts and statistics about the world.”
Caliskan's work, together with coauthors Joanna Bryson and Arvind Narayanan, was published last week in Science. Essentially, they found that if someone trains a machine to understand human language, then it's going to pick up those inherent biases as well.
In humans, one of the best ways to test for bias is the implicit association test, which asks people to associate a word like “insect” with a word like “pleasant” or “unpleasant” and then measures the latency, or the time it takes to make that connection. People are quick to label insects as unpleasant and slower to label them as pleasant, so it's a good metric for associations.
Testing hesitation in a computer doesn't really work, so the researchers found a different way to see what words computers are more willing to associate with others. Like students guessing at the meaning of an unfamiliar word based only on the words that appear near it, the researchers trained an AI to associate words that appear close to each other online, and to not associate words that don't.
Imagine each word as a vector in three dimensional space. Words commonly used in the same sentences are closer to it, and words rarely used in sentences with it are vectors farther away. The closer two words are, the more likely the machine associates them. If people say "programmer" close to "he" and "computer" but say "nurse" close to "she" and "costume," that illustrates the implicit bias in language.
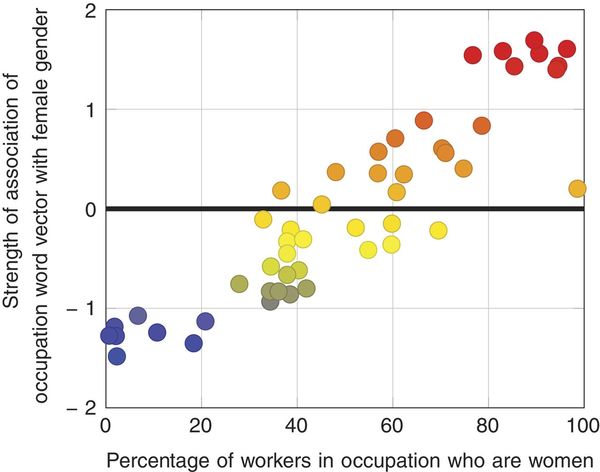
Caliskan et al
Profession names associated with women have more women workers
On the x-axis, data from the U.S. Bureau of Labor Statistics shows the percentage of women in an occupation. On the y-axis is the strength of word associations with the profession in a major online word usage data set.
Feeding computers this kind of language data in order to teach them isn't a new concept. Tools like Stanford's Global Vectors for Word Representation—which existed before this paper—plot vectors between related words based on their use. GloVe's wordsets include 27 billion words pulled from 2 billion Tweets, 6 billion words pulled from Wikipedia in 2014, and 840 billion words pulled from a random trawl through the internet.
“You could say “how many times does 'leash' occur near 'cat?'” and “how many times does 'leash' occur near 'dog?'” and “how many times does 'leash' occur near 'justice?'”, and that would be part of the characterization of the word,” Bryson said. “And then these vectors, you can compare them with cosines. How close is cat to dog? How close is cat to justice?”
Just as an implicit association test shows what concepts a human unconsciously thinks of as being good or bad, the calculation of the average distance between different groups of words showed researchers what biases a computer had started to show in its understanding of language. It's remarkable that machines trained to understand language picked up on human biases about flowers (they're pleasant) and insects (they're unpleasant), and Bryson said it would be a significant study if that was all it showed. But it went deeper than that.
“There's a second test, which is measuring the quantity between our findings and statistics that are made public,” said Caliskan. “I went to 2015's Bureau of Labor Statistics, and every year they publish occupation names along with percentage of women and percentage of, for example, black Americans in that occupation. By looking at the makeup of 50 occupation names and calculating their association with being male or female, I got 90 percent correlation with Bureau of Labor data, which was very very surprising, because I wasn't expecting to be able to find such a correlation from such noisy data.”
So computers are picking up on racism and sexism by associating job-related words with a particular gender or ethnic group. One example emphasized in the paper is “programmer,” which is not a gendered word in English, yet through its use now has connotations of being a male profession.
“We hadn't thought, when you're saying programmer are you saying male or are you saying female,” said Bryson, “but it turns out it's there in the context in which the word normally occurs.”
Machines trained on datasets of language as it's used (like GloVe) will pick up on this association, because that is the present context, but it means researchers in the future should be cautious about how they use that data, since the same human bias comes baked-in. When Caliskan trained the tool on the Wikipedia wordset, which is held to a neutral language editorial standard, she found that it contained the same bias she found in the larger set of words pulled from the internet.
Caliskan et al
Word association matches gender breakdown of androgynous names
Looking at a set of androgynous names (Like "Alex" and "Taylor"), the researchers found that the close a name was associated with the female gender online, the greater the percentage of people who had that name were women.
“In order to be aware of bias, in order to unbias, we need to quantify it,” Caliskan said, “How does bias get in language, do people start making biased associations from the way they are exposed to language? Knowing that will also help us find answers to maybe less biased future.”
One answer may be looking to other languages. The study focused on English-language words on the internet, so the biases it found in word use are the biases, generally, of English-speaking people with access to the internet.
“We are looking at different types of languages and based on the syntax of the language we are trying to understand if it affects gender stereotypes or sexism, just because of the syntax of the language,” said Caliskan. “Some are genderless, some are little more gendered. In English there are gendered pronouns, but things get more gendered [in languages] such as German where the nouns are gendered, and it can go further. Slavic languages have gendered adjectives or even verbs, and we wonder, how does this affect gender bias in society?”
Understanding how bias gets into a language is also a way of understanding what other, implicit meanings people add to words besides their explicit definitions.
“In a way this is helping me think about consciousness,” said Joanna Bryson, one of the authors on the study. “What is the utility of consciousness? You want to to have memory of the world, you want to know what kind of things normally happen. That's your semantic memory.”
The mutability of language, the way semantic context is formed through use, means this doesn't have to be the only way we understand this world.
“You want to be able to create a new reality,” continued Bryson. “Humans have decided that we've got our stuff together well enough now that we could have women working and developing careers and that's a perfectly plausible thing to do. And now we can negotiate a new agreement, like, “we're not going to say 'the programmer he', we're gonna say 'the programmer they', even if we're talking about singular, because we don't want to make people feel like they can't be programmers.”
And unless people account for these existing biases when programming machines on human language, they'll create not an unbiased machine, but a machine that replicates human bias.
“Many people think machines are neutral,” said Caliskan. “Machines are not neutral. If you have a sequential algorithm that's making decisions sequentially, like machine learning, you know that it is trained on a set of human data, and as a result it has to present and reflect that data, since historical data includes biases, the trained models will have to include those biases as well, if it's a good training algorithm. If it's accurate enough, it will be able to understand all those associations. The machine learning system learns what it sees.”






EDITOR'S PICKS
